FinTabNet
| Image (screenshot of PDF, see notebook for details on how to extract image from PDF) | Annotated Image (Generated with Notebook) | JSON label | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
 |
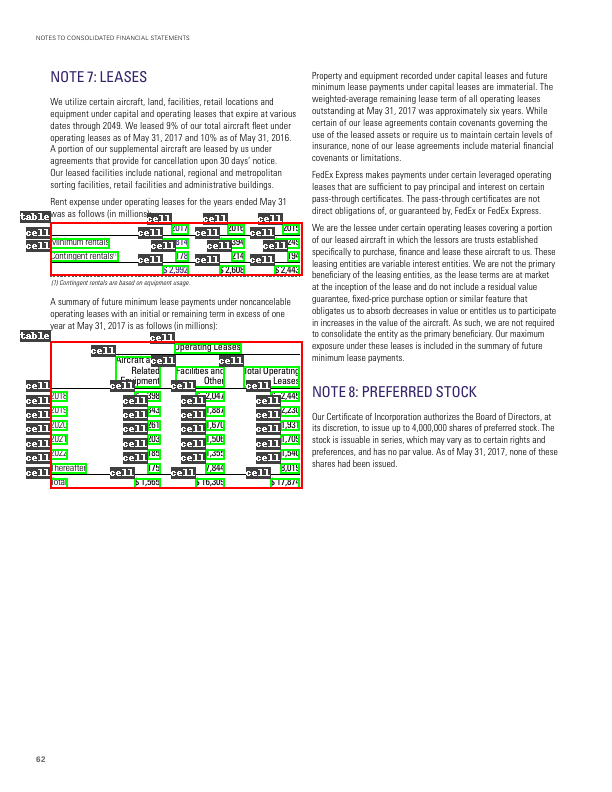 |
|
| Feature | Description |
|---|---|
|
|
Folder containing all the PDFs sorted by company stock ticker and year (subfolder) |
|
annotations |
Each table instance annotation contains a series of fields, including the HTML structure and bounding box coordinates of the table. This information is in the JSON file and the top level file/list is henceforth referred to as annotations |
|
annotations -> table_id |
A unique ID assigned to each table in the dataset. |
|
annotations -> html -> structure |
describes the HTML structure of the table |
|
annotations -> html -> cells |
contains the actual values inside the table cells. This is the information present in the table. |
|
annotations -> split |
test/train/val split |
|
annotations -> filename |
the name of the underlying PDF file where this table is from. |
|
annotations -> bbox |
the bounding box coordinates (in the PDF file) for the particular table. |